On the Airtable forum, Stephen Orr requested a new feature similar to the ALL() formula in Excel.
A formula that returns a comma-separated list of all values across records in a view for a given field :
ALL({some field})
This is a reasonable feature request. I made a similar request in 2018 for Split() . That was 2,160 days ago. Still waiting. I hope Stephen is more successful in getting Airtable’s attention.
What he’s asking for is tantamount to a Parquet data format, which is one of the fastest file types to read generally and much faster than either JSON or CSV. It’s like a pivot table - fields are listed down the data structure, and columns are represented as arrays for each field. Stephen only wants a single column’s values as an array, and Airtable should accommodate this. All() makes sense, especially in data sciency activities.
The advantages of a Parquet data format are significant, and it’s no coincidence that Pandas data frames can read and write this format. It puts the science in data science for these reasons:
- Compression
- Performance
- Schema evolution
- Open source/non-proprietary
Enough about Parquet. Here’s why it’s relevant to Stephen’s feature request.
Given a table like this, he wants a column transformed into an array.
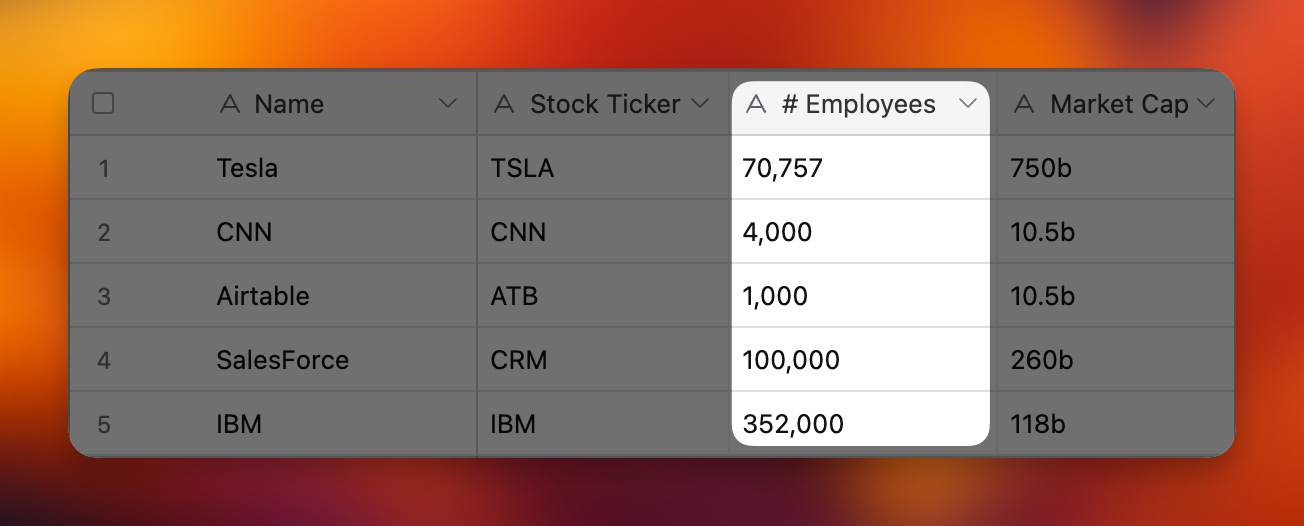
A Parquet table looks like this.
“Name”: [“Tesla”, “CNN”, “Airtable”, “SalesForce”, “IBM”],
“Stock Ticker”: [“TSLA”, “CNN”, “ATB”, “CRM”, “IBM”],
“# Employees”: [70757, 4000, 1000, 100000, 352000],
“Market Cap”: [750000000000, 10500000000, 1050000000, 260000000000, 118000000000]
How’d I get this? AI (of course). ![]()
I often do this - find a development need and see if an LLM can do it. Many of these experiments are nutty, but I learn something in all of them. In this case, I was actually surprised at how well Google’s LLM addressed the requirement. Will it be valid at scale? I don’t know.

By simply transforming the Airtable table into Markdown, I had the Parquet table in a few seconds. I probably could have used CSV instead.

Taking this to the next level, Stephen’s data objective is now within reach.

As you may have experienced, pushing data into an LLM and asking for discrete values with accuracy is difficult. With Parquet, there are some advantages.
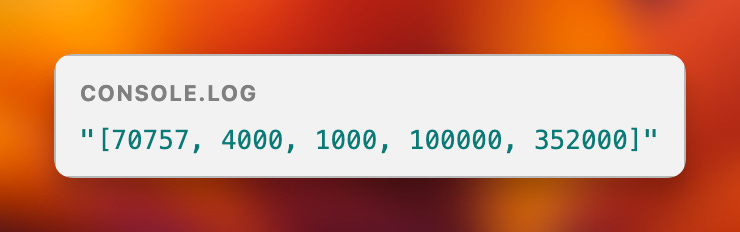
Revisiting Split()
I no longer want Split(). I want a feature to perform inline inferencing against a blistering fast LLM such as PaLM 2.
Let’s take the list of values we created for Stephen’s case and parse it into an actual array.
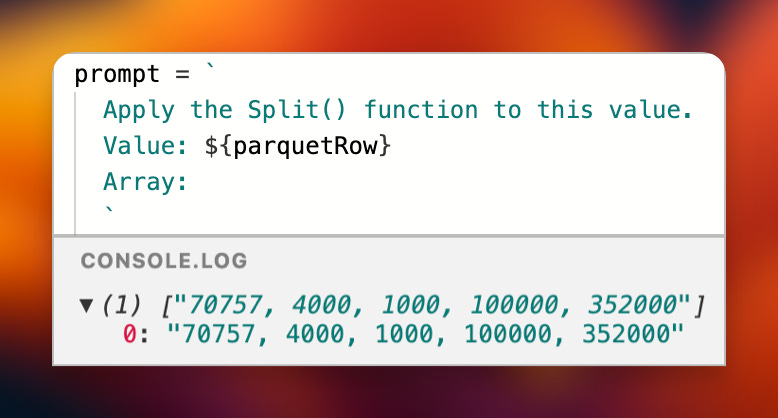
The Feature to End All Features?
Indeed, there are many ways to extract these values, either through a script or formula if Airtable gets around to it. This article is not about a methodology for managing or working with data. Instead, it’s about the possible future of platform features.
This example demonstrates that vendors should think carefully about implementing new features because it may be possible to end the feature request madness by simply adding one feature - ai() .
Can it be that simple? Hardly, but developers and platform vendors should consider how AGI will transform their architectures.